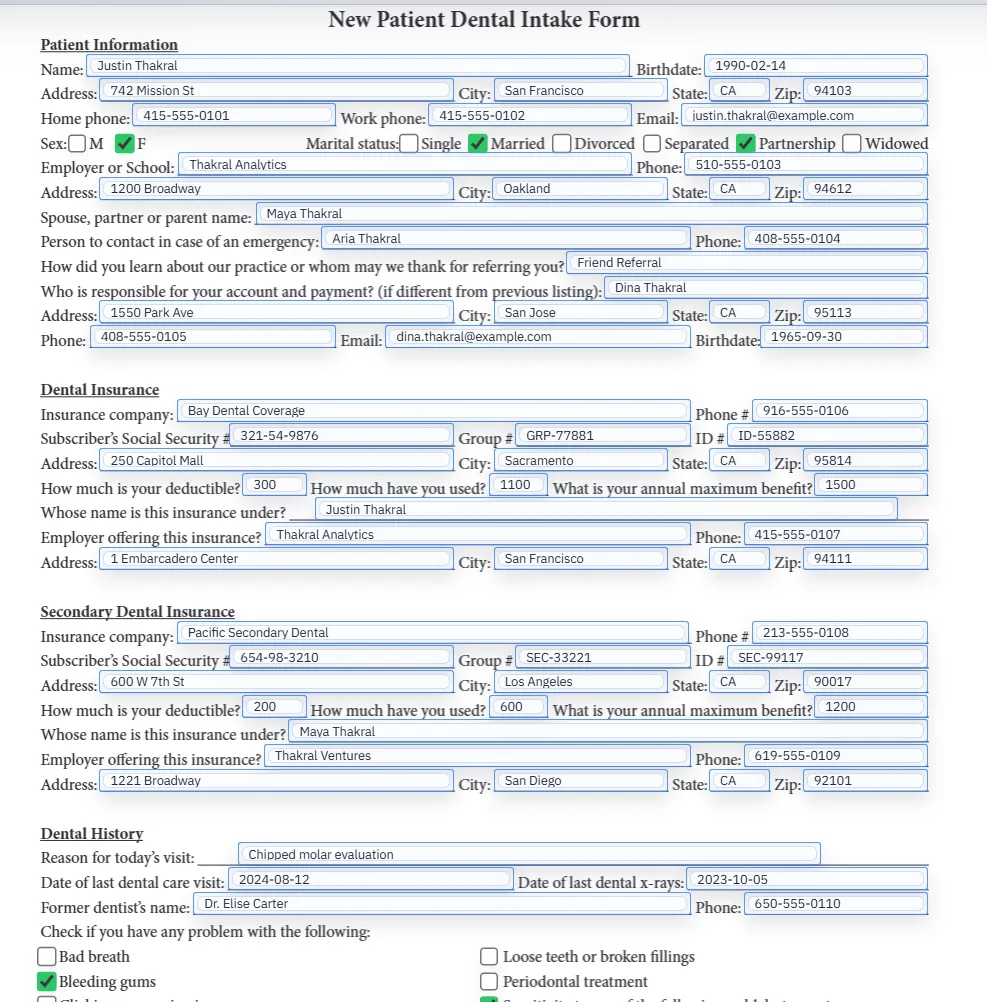
The Node.js teams that get the most out of an external PDF fill API tend to share a shape. They have an existing CRUD or workflow app where the user has just submitted a form, finished an order, completed a benefits enrollment, or signed a contract. They need to render that record into a specific PDF — an ACORD certificate, an HR onboarding packet, a fillable government form, a generated invoice — and either email it, store it, or hand it back to the user.
In that shape, every native PDF library forces you to think about field positions, font embedding, encryption, and AcroForm internals. An external API replaces that with one HTTPS call and a JSON payload that mirrors the database row you already have. That removes most of the surface area where in-house PDF code goes wrong.
- Insurance back-office: render a filled ACORD 25 from the policy record after binding.
- HR / staffing: render a populated I-9 + W-4 packet on hire-confirmed.
- Healthcare-adjacent (non-PHI): render an intake summary PDF for the customer record.
- Internal ops: scheduled job renders 50 filled certificates from yesterday's submissions.