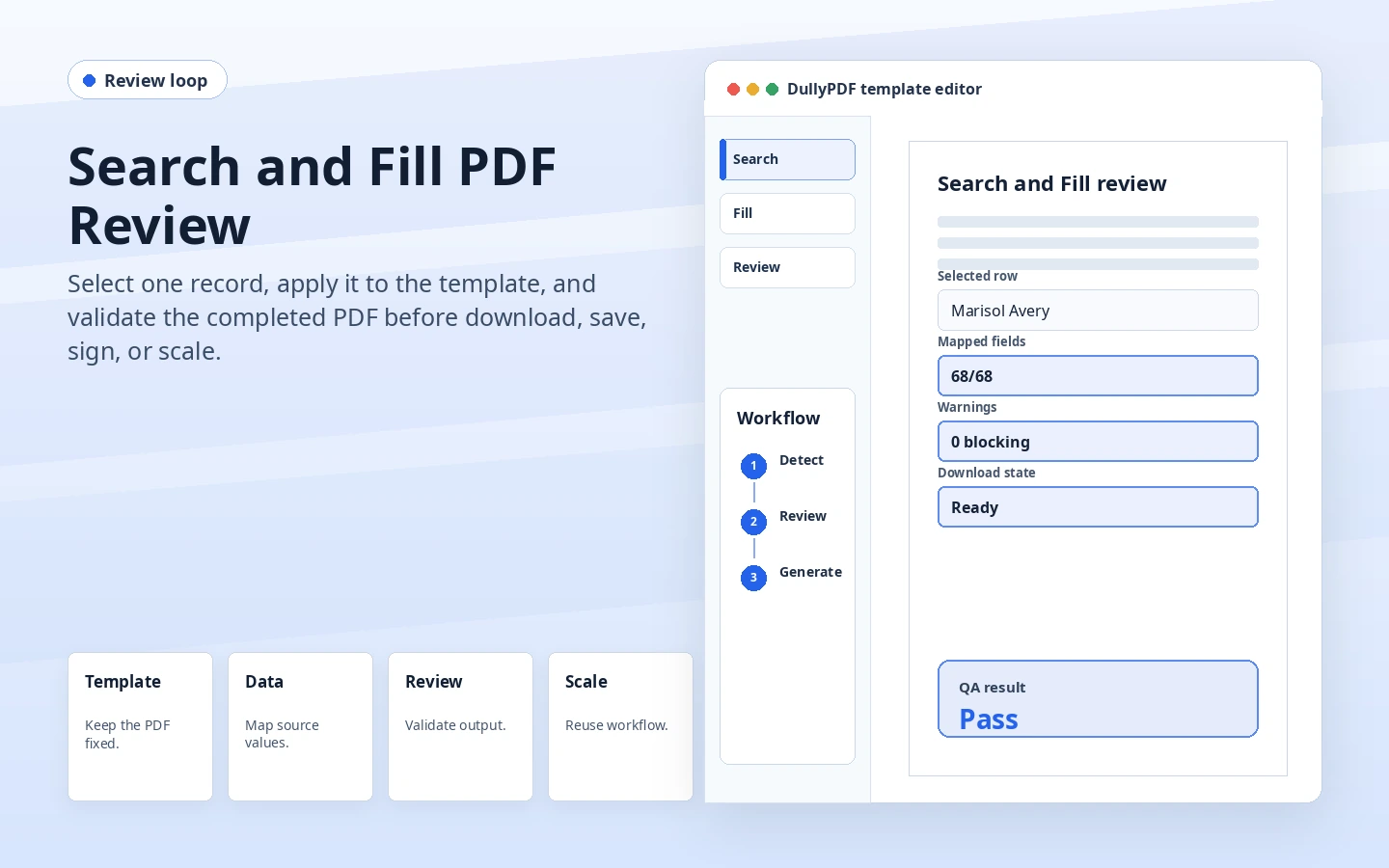
Why teams use India CSV to PDF Forms
- Use CSV exports when another system owns the record but staff still needs a reviewed PDF output.
- Map headers such as gstin, pan_number, branch_code, invoice_number, and challan_number into stable fields.
- Validate one row visually before producing a batch of flat PDFs.