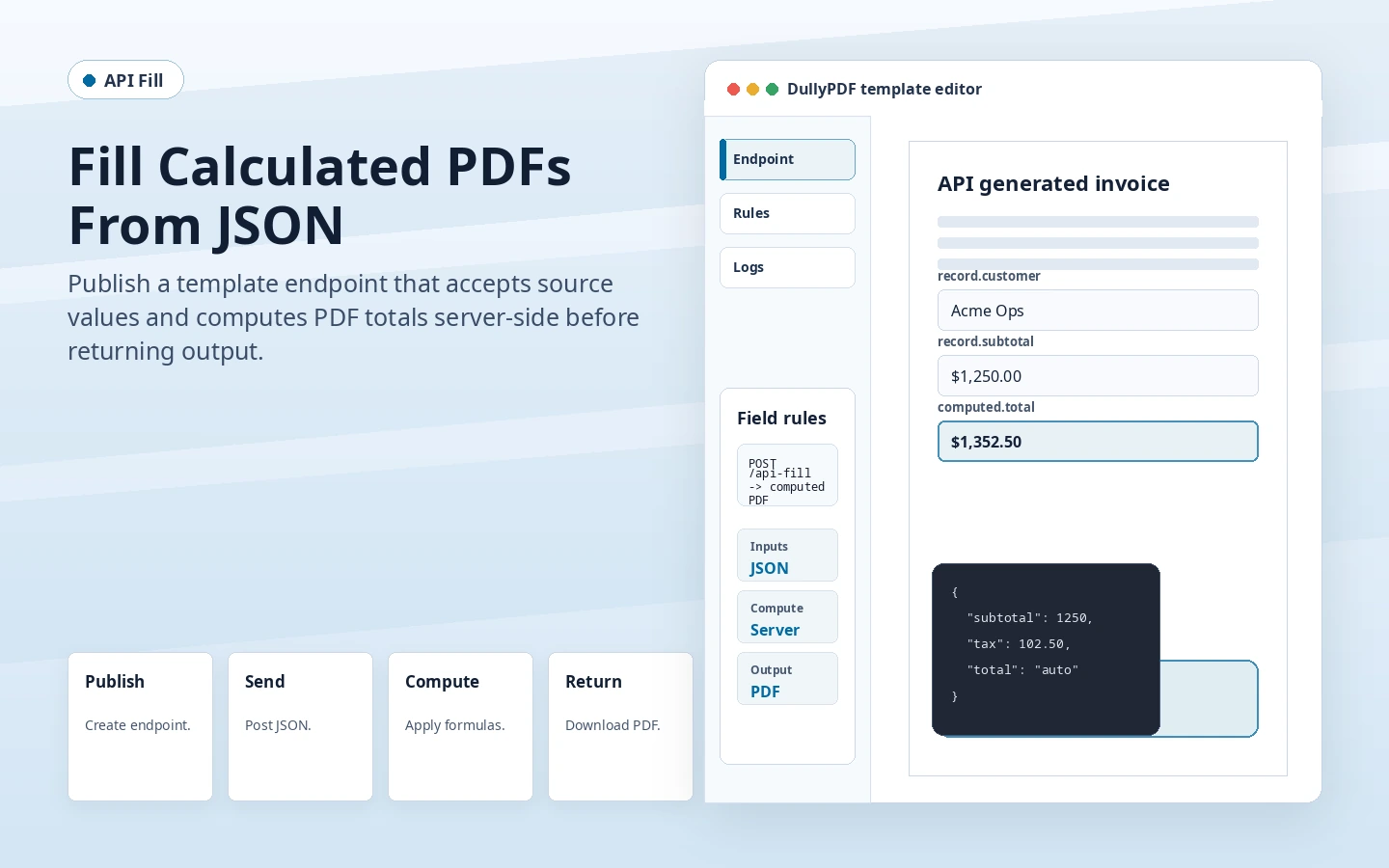
A caller should send only the source fields the template expects. For an invoice, that might be customer_name, quantity_1, unit_price_1, tax_rate, discount, and amount_paid. The response PDF can include line_total_1, subtotal, tax_amount, grand_total, and balance_due even though the caller did not send those derived fields.
This separation makes the endpoint easier to validate. Missing source inputs are request errors. Calculated output inputs are either rejected in strict mode or ignored in non-strict mode because the template formula owns those values.