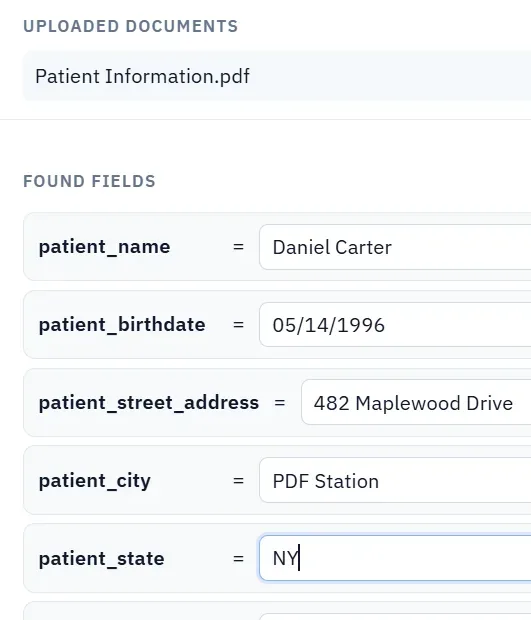
A useful openai data boundaries test starts with one document your team already recognizes, not a perfect demo PDF. Open the existing file, review detection, rename ambiguous fields, confirm checkbox and radio behavior, and save the template only after the field list matches the way the document is used in practice.
Then fill one representative record end to end. Include long names, blank optional values, dates, yes/no choices, and any calculated or scannable fields the page depends on. That single controlled run exposes most template issues before they become repeated output problems.