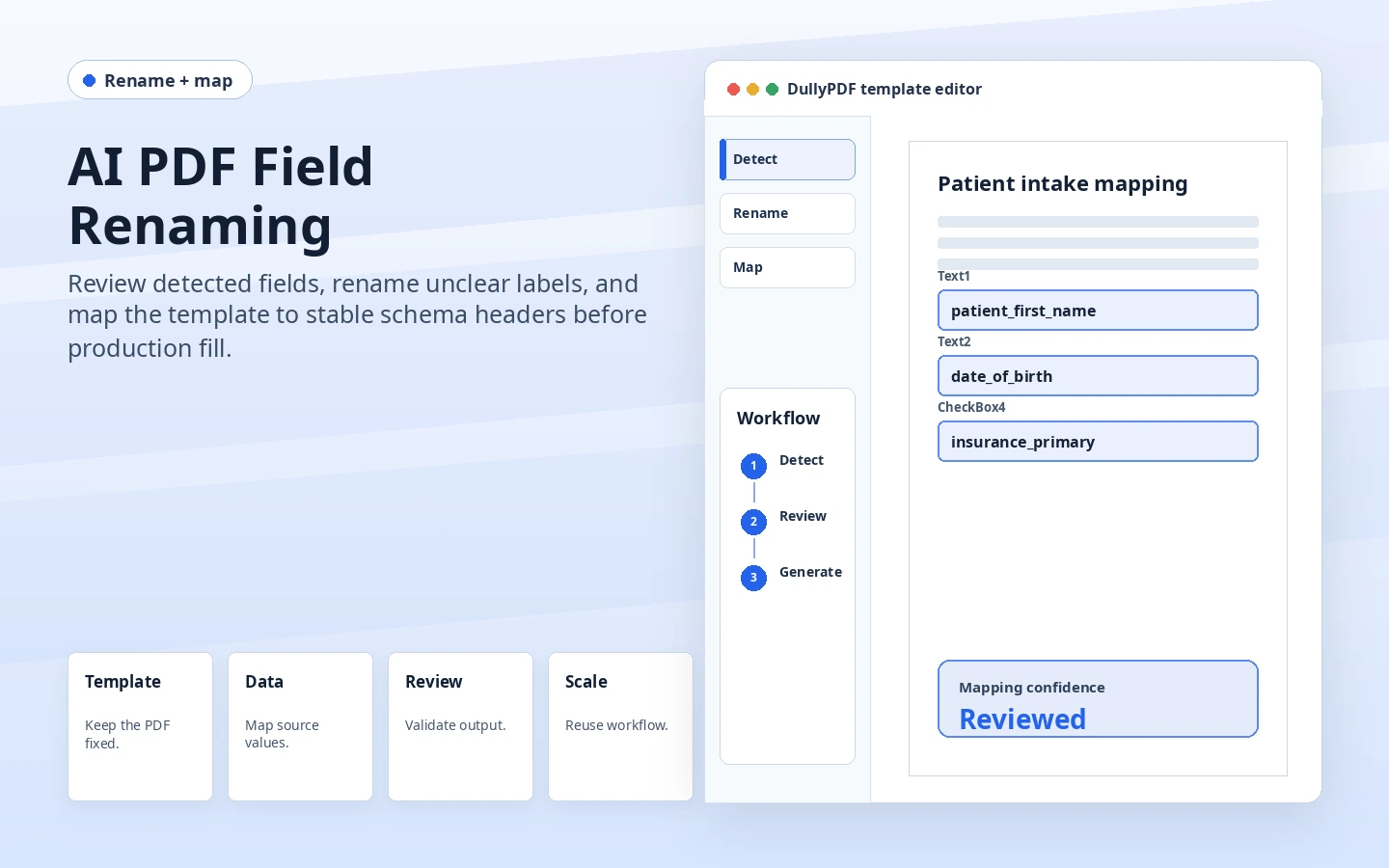

Why teams use AI Field Renaming
- Convert vague or duplicated PDF widget names into reviewable template names.
- Map fields to schema headers so Search & Fill, API Fill, and stored responses target the right places.
- Review confidence and checkbox/radio behavior before a template becomes reusable.