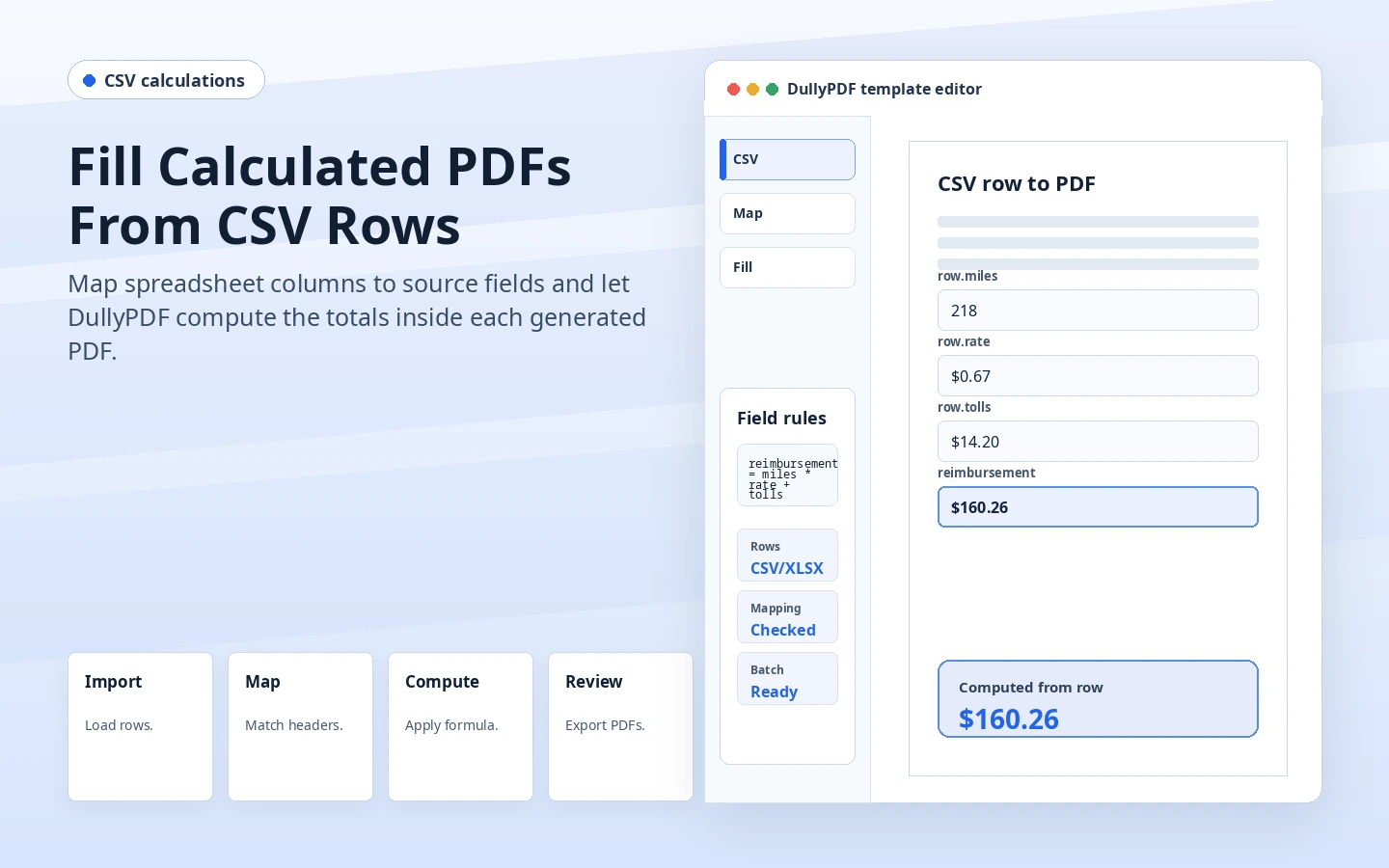
A spreadsheet can already contain totals, but copying those totals into a PDF creates two sources of truth. If the spreadsheet formula changes, if a column is stale, or if an operator edits one value by hand, the PDF can stop matching the source inputs.
DullyPDF works better when the spreadsheet provides the source values and the template computes the derived values. Quantity, rate, hours, fee, discount, and deposit can come from the row. Subtotal, grand total, amount due, or score total can be calculated by the PDF template when the file is generated.